Long-Term Retention
Recordings’ content can be automatically uploaded to an immutable data store for long-term retention. Data may be stored in either Amazon S3 or Google Cloud Storage (GCS). Uploads can be triggered automatically at the end of a recording or on-demand at the user’s discretion.
To enable either automatic or on-demand uploads, simply add the appropriate credentials. Once the proper credentials are in place, the recording’s content will be uploaded:
- When the recording ends
- Once an hour
- On-demand at the user’s discretion
Triggering an Upload On-demand
Users can utilize the Jobs dashboard to initiate an on-demand upload of the tar files. Simply press the Run All Jobs button to compress and upload all accumulated content.
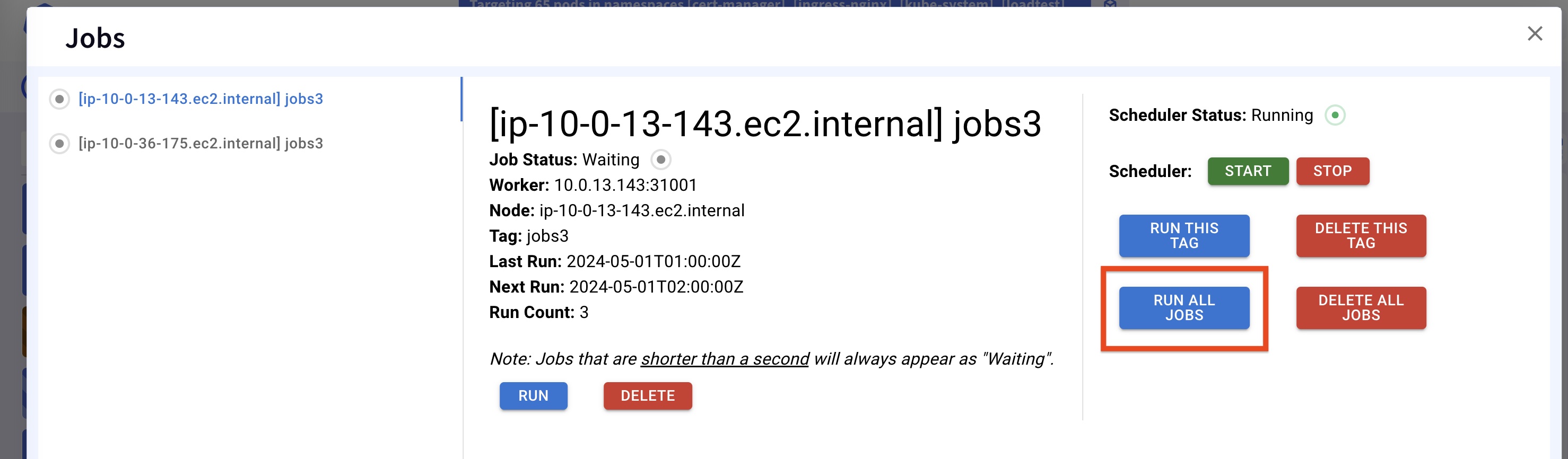
Automatic Upload
By default, content is uploaded hourly and at the end of the recording window, as long as the proper crednetials are in place.
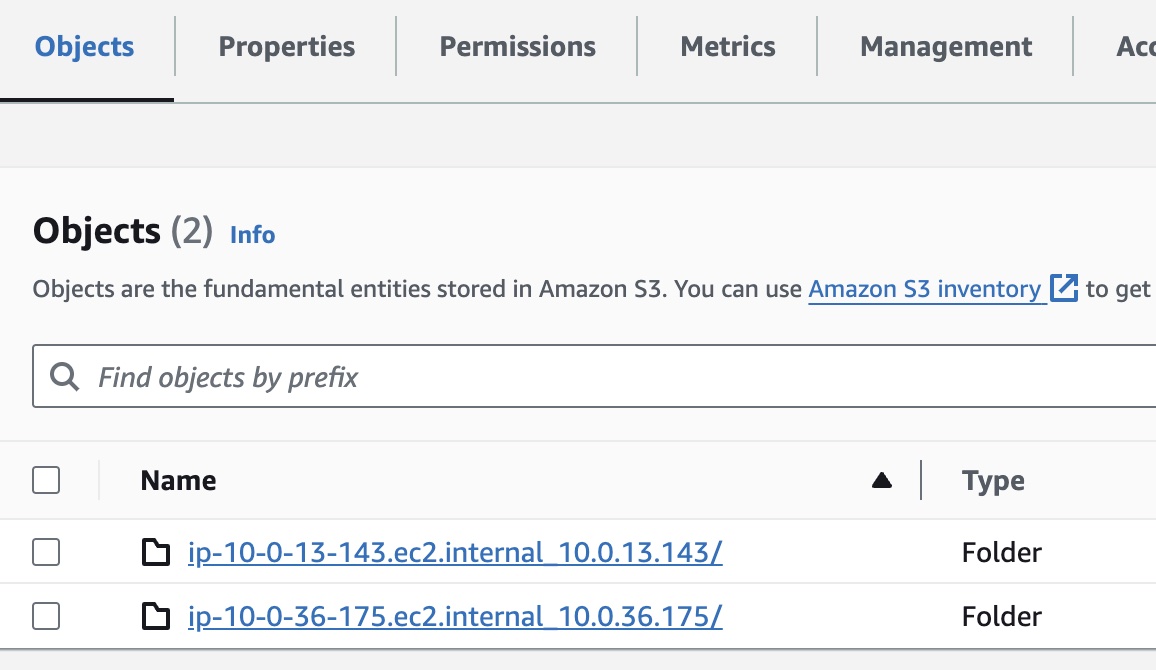
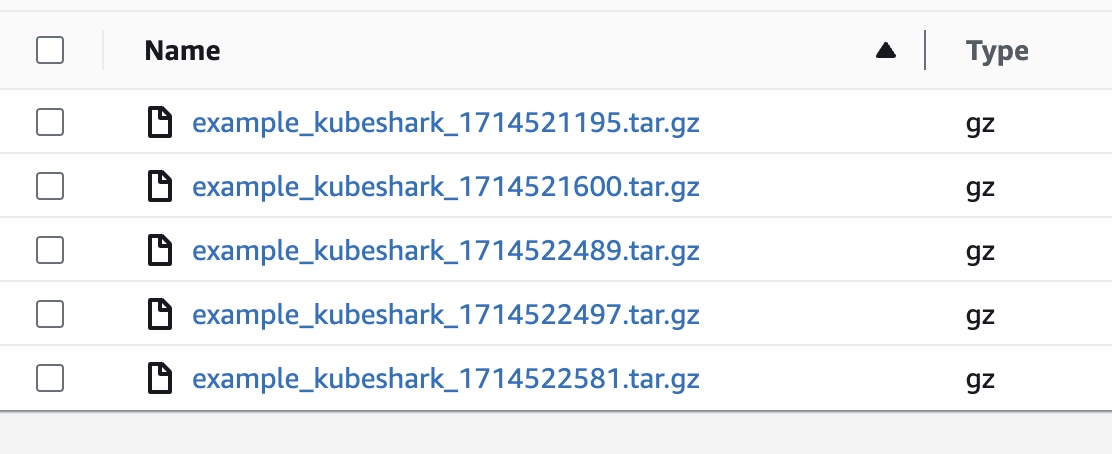
Bucket Content
Within the bucket, you can expect a folder per node, where each folder contains a tar file for each upload, following this pattern:
<node>/<recording-name>_kubeshark_<timestamp>.gz.tar
For example:
Content of the Tar File
Each tar file includes all JSON files and PCAP files that belong to the traffic recording.
Use Specific Auth Credentials
- S3_BUCKET: The name of the S3 bucket
- AWS_REGION: The region where the bucket resides
- AWS_ACCESS_KEY_ID: AWS Access Key
- AWS_SECRET_ACCESS_KEY: AWS Secret Access Key
Learn more about the required AWS credentials here.
Configuration Example
In either config.yaml or values.yaml, the environment variable should look something like this:
scripting:
env:
S3_BUCKET: <bucket-name>
AWS_REGION: <bucket-region>
AWS_ACCESS_KEY_ID: AK..4Z
AWS_SECRET_ACCESS_KEY: K..rAWS S3 IRSA or Kube2IAM
In scenarios using shared authentication (e.g., IRSA, kube2iam), the S3 helper will utilize the default authentication method and will not require specific AWS Auth credentials. In these cases, the required credentials include:
- S3_BUCKET: The name of the S3 bucket
- AWS_REGION: The region where the bucket resides
Read more about IRSA in this article.
GCS
Uploading to GCS requires the following credentials:
- GCS_BUCKET: GCS Bucket
- GCS_SA_KEY_JSON: GCS Key JSON
Configuration Example
In either config.yaml or values.yaml, the environment variable should look something like this:
scripting:
env:
GCS_BUCKET: <bucket-name>
GCS_SA_KEY_JSON : '{
"type": "service_account",
"project_id": <project-id>,
"private_key_id": "14a....81",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvQIBADANBgkqhkiG9w0.....HBJsfVHn\nRvUJH6Yxdzv3rtDAYZxgNB0=\n-----END PRIVATE KEY-----\n",
"client_email": "k..om",
"client_id": "104..72",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/k...nt.com",
"universe_domain": "googleapis.com"
}'